Startseite > Altgriechisch und Latein auf dem Computer > Kodierungen des Griechischen
![]() Michael Neuhold Homepage
Michael Neuhold Homepage
Startseite >
Altgriechisch und Latein auf dem Computer >
Kodierungen des Griechischen
An Englisch version of this page is available.
Diese Seite beschreibt einige der wichtigsten Möglichkeiten, griechische Texte mit Akzenten auf Computern digital zu kodieren, und inwieweit diese von greekconverter unterstützt werden.
Kodierung mit 16-Bit-Zeichen, auf dem Wege zu einem weithin akzeptieren Standard. Die kanonische Darstellung von Buchstaben mit diakritischen Zeichen ist eine Abfolge des Buchstabens gefolgt von seinen diakritischen Zusatzzeichen. In vielen Fällen (z.B. beim Griechischen) existieren viele mögliche Kombinationen von Zeichen und diakritischen Zeichen auch als zusammengesetzte (precomposed) Zeichen (vermutlich aus Gründen der Kompatibilität mit anderen Kodierungssystemen und um die Herstellung von Fonts zu erleichtern). Die Stapelabfolge (stacking order) für griechische Diakritika ist: Hauchzeichen - Akzent - Iota subscriptum bzw. Trema (Diaeresis) - Akzent. Nehmen wir z.B. den Dativ Singular des weiblichen Artikels:
| Kanonisch: 03C4 - 03B7 - 0342 - 0345 | |
| Teilweise zusammengesetzt: 03C4 - 1FC6 - 0345 | |
| Teilweise zusammengesetzt, andere Möglichkeit: 03C4 - 1FC3 - 0342 | |
| Vollständig zusammengesetzt: 03C4 - 1FC7 |
Nur die letzte Möglichkeit wird von den Konvertierungsprozeduren von greekconverter vollständig unterstützt. Denn in Unicode ist jede Kombination erlaubt, auch wenn sie kein gültiges griechisches Zeichen darstellt. Wie soll z.B. Alpha + Gravis + Akut + Zirkumflex bei der Konvertierung behandelt werden?
Unicode hat zweifelsohne eine Menge Vorzüge, aber auch Nachteile. Es laboriert vor allem an dem Versuch, zu allem kompatibel zu sein. Denn viele Zeichen sind mehrmals mit unterschiedlichen Codes definiert. Wer weiß, wann er welches Zeichen verwenden muß oder in was er es konvertieren soll. Nehmen wir z.B. das Zeichen, das wie ein spatiierender (spacing) (d.h. als eigenes Zeichen verwendeter, nicht den vorherigen Buchstaben veränderndes diakritisches Zeichen) Akut - ´ - aussieht:
00B4 ACUTE ACCENT: ist ein Akut (spacing), keine Frage.0384 GREEK TONOS: der einzige in modernem Griechisch
verwendete Akzent (hier definiert aus Gründen der Kompatibilität
zu ISO-8859-7?).1FFD GREEK OXIA: einer der drei Akzente des Altgriechischen,
laut Unicode-Zeichenlisten identisch mit 00B4 ACUTE ACCENT
(hier wiederum aus Kompatibiltätsgründen definiert?).02CA MODIFIER LETTER ACUTE ACCENT: verwendet für hohen
Ton, primären Druck (primary stress); was also ist der Unterschied zu
00B4 ACUTE ACCENT?2032 PRIME: verwendet als Abkürzung für Minuten
und Fuß.02B9 MODIFIER LETTER PRIME: verwendet für primären
Druck und Nachdruck (emphasis) - das ist also eine Art von Akzent - oder?0374 GREEK NUMERAL SIGN: zeigt an, daß griechische
Buchstaben als Zahlen verwendet werden; die Unicode-Zeichenlisten sagen,
dies sei identisch mit 02B9 MODIFIER LETTER PRIME, aber das
wird verwendet für Nachdruck, was etwas ganz anderes ist.Detailierte Zeichenlisten sind verfügbar beim Unicode Consortium. Die folgenden Tabellen sollen nur einen ersten Eindruck vermitteln.
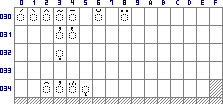 Sich verbindende (combining) diakritische Zeichen (0300-036F). Den grauen Positionen sind keine Zeichen zugeordnet, an den leeren Positionen sind Zeichen, die normalerweise nicht in griechischen Texten vorkommen. Man beachte, daß Zirkumflex (0302), Tilde (0303) und Perispomeni (0342) drei verschiedene Zeichen sind. |
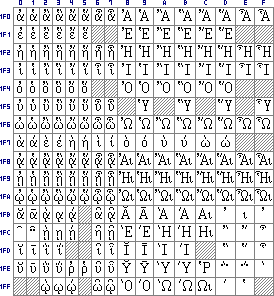 Erweitertes Griechisch (1F00-1FFF). In früheren Versionen der offiziellen Unicode-Zeichenlisten war das Iota adscriptum unter die Großbuchstaben subskribiert, in der aktuellen Version ist es adskribiert (wie in Textausgaben üblich). Dies scheint nur eine Variation der Schriftgestaltung zu sein. |
 Griechisch und Koptisch (0370-03FF). Die leeren Positionen sind die nur dem Koptischen eigenen Buchstaben, die zu zeichnen ich zu faul war. |
Unicode definiert nur die Zuordnung eines Zeichens zu einem Zahlenwert, aber nicht, wie dieser Zahlenwert verspeichert wird (Anzahl Bytes, Byteorder usw.). Hierfür gibt es die UTF (Unicode Transformation Format). In UTF-8 z.B. werden Zeichen aus dem Bereich US-ASCII nur mit einem Byte abgespeichert. Das hat den Vorteil, daß diese Zeichen auch ein nicht Unicode-fähiger Editor korrekt interpretieren kann.
7-Bit-sichere Kodierung die nur Zeichen des US-ASCII-Zeichensatzes verwendet.
Jedes diakritische Zeichen wird durch einen eigenen Buchstaben dargestellt
(Ausnahmen gibt es lediglich bei einigen spatiierenden diakritischen Zeichen).
Das obige Beispiel in Betacode: TH=|
(oder th=|) - Gleichheitszeichen steht
für Zirkumflex, senkrechter Balken für Iota subscriptum.
Griechischer Betacode unterscheidet nicht zwischen Klein-/Großschreibung,
Griechische Großbuchstaben werden durch Voranstellung von *
bezeichnet. Einige Projekte benutzen nur Großbuchstaben (z.B. TLG,
für das Betacode erfunden wurde), andere nur Kleinbuchstaben (z.B. das
Perseus Project).
Ich habe nicht herausgefunden, ob es eine bestimmte Stapelanordnung für
diakritische Zeichen gibt. Aber alle Beispiele, die ich bisher gesehen habe,
verwenden: Hauchzeichen - Akzent - Iota subscriptum bzw. Akzent - Trema
(letzteres unterscheidet sich von Unicode). Bei Großbuchstaben stehen
die Diakritika zwischen dem * und dem Buchstaben selbst (z.B.
*)/ARHS), ansonsten werden sie dem Buchstaben nachgestellt
(z.B. A)/RSHN).
Ähnlich wie Unicode kodiert Betacode Zeichenfunktionen, nicht Glyphen (konkretes Aussehen von Zeichen). Daher kann eine Glyphe verschiedenen Zeichenfunktionen entsprechen. Die folgenden drei Zeichen sehen alle aus, wie ein Schrägstrich - / -:
%3: Schrägstrich (slash), normaler typographischer
Gebrauch#17: Lineola obliqua, antikes Editorenzeichen#804: 1/12 OboleBetacode verfügt über eine Menge sogenannter Escapesequenzen für editoriale, papyrologische, inschriftliche, mathematische, musikalische, astronomische, metrische usw. Zeichen und Symbole. Die meisten von ihnen haben keine Entsprechung in Unicode (zumindest keine, von der ich wüßte) und werden daher von greekconverter nicht unterstützt.

Betacode-Zeichenbelegung in Auszügen
Transliteration mit ASCII-Zeichen, die die meisten diakritischen Zeichen
übergeht (außer daß Spiritus asper als h wiedergegeben
wird) und einige Zeichen in Abhängigkeit vom vorhergehenden Zeichen
wiedergibt (z.B. Alpha-Ypsilon meistens als au).
![]()
Ersetzungstabelle für die Transliteration. Für Eta und Omega wird
oft auch einfach e und o genommen (kein Unterschied zu Epsilon und Omikron).
Seit Version 4.0 benützt HTML den sog. Universal Character Set (UCS),
der auf dem Unicode-System beruht. Somit kann jedes beliebige Unicode-Zeichen
als numerische Entität notiert werden, entweder dezimal in der Form
ü oder hexadezimal als ü. Für
Buchstaben ohne Akzente gibt es benannte Entitäten wie α.
Das obige Beispiel mit HTML-Entitäten:
τῇ
(zusammengesetzt, benannte und hexadezimale numerische Entitäten) oder
τῇ
(kanonisch, nur dezimale numerische Entitäten).
Alternativ dazu kann man die HTML-Datei im Unicodeformat erzeugen und
dem Browser mitteilen, wie er den Inhalt der Datei interpretieren muß,
indem man die Charset-Eigenschaft in einem Meta-Tag im Head-Abschnitt
der HTML-Seite setzt:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
Proprietäre 8-Bit-Kodierung, optimiert für die Anzeige von
Bibeltexten mit TrueType-Schriften, ähnlich wie Betacode. Das obige
Beispiele in BibleWorks: th/|.
Wenn man eine der griechischen TrueType-Schriften verwendet, die mit
BibleWorks mitgeliefert werden (© Michael Bushell), dann werden die
sich verbindenden diakritischen Zeichen mit Hilfe von Kerning über
oder unter das vorhergehende Zeichen gesetzt.

Die Zeichenbelegung von BibleWorks, erschlossen aus der griechischen
TrueTrype-Schrift Bwgrkn, im Vergleich zur Zeichenbelegung von Latin-1.
Die TrueType-Fonts SPIonic (© Scholars Press) und Sgreek (© Silver Mountain Software) verwenden im wesentlichen die Zeichenbelegung von Betacode. Diakritische Zeichen werden wie bei BibleWorks durch Kerning positioniert. Es bestehen allerdings folgende Abweichungen von Betacode:
Sgreek hat wesentlich mehr Varianten als SPIonic, und natürlich an ganz anderen Positionen. Zwischen Sgreek Medium und Sgreek Fixed gibt es ein paar marginale Unterschiede, einer ist aber wichtig: das Pipe-Zeichen | produziert in Sgreek Medium kein Iota subscriptum, sondern eben ein Pipe-Zeichen. Man muß bei Sgreek Medium also #, $ und % verwenden.

Die Zeichenbelegung von SPIonic. Die gelb hinterlegten Zeichen sind Varianten
mit geringerem Kerning. Man beachte, daß SPIonic keine Ziffern enthält.
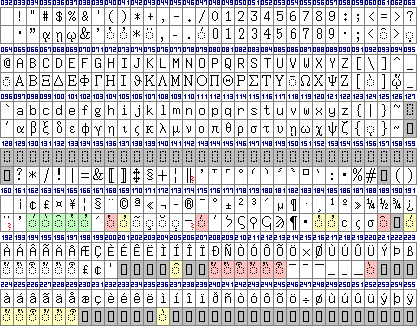
Die Zeichenbelegung von Sgreek Fixed. Die gelb hinterlegten Zeichen sind
Varianten mit geringerem, die rot hinterlegten mit stärkerem Kerning
als die Standardzeichen. Die grün hinterlegten Zeichen haben die
Glyphen etwas höher positioniert. In einigen Fällen zeigt die
Windows-Zeichentabelle etwas anderes an als WinWord. Mir ist nicht klar,
was von beidem beabsichtigt ist.
Die Konvertierung nach SPIonic/Sgreek unterstützt nur die Zeichen, die auch in Betacode so definiert sind. Mit anderen Worten: die Kerningvarianten und die zusammengesetzten Zeichen werden nicht berücksichtigt.
8-Bit-Kodierung, ein Quasi-Standard auf Apple-Computern bis OS 9 (seither unterstützt MacOS Unicode). Es vermeidet Kerning und benutzt stattdessen nur zusammengesetzte Zeichen. Das hat den Nachteil, daß Konstrukte wie MNE=MA IATRO= (Grabmal eines Arztes, verwendet in der Wiedergabe von Inschriften) nicht angezeigt werden können.

Die Zeichenbelegung von GreekKeys, erschlossen aus der TrueType-Schrift
Athenian (© American Philological Association). Man bemerke, daß
DisplayGreek A(=| konsequenterweise an Position 160 hat, während es bei
Athenian auf 170 liegt.
Die offiziellen Unicode-Zeichennamen stellen keine eigene Kodierung dar, aber greekconverter kann sie ausgeben, um eine menschenlesbare Ausgabe von fehlerhaftem Unicode erzeugen zu können, der auf andere Weise nicht konvertiert werden kann.
Viele Konvertierungen kann man durch Mehrfachkonvertierung erreichen, z.B. BibleWorks in GreekKeys: BibleWorks -> Unicode -> GreekKeys.
Gegenwärtig nicht unterstützt werden Kodierungen, die für ein einzelnes Programm erfunden wurden, wie Logos, WinGreek etc.
Autor:
(E-Mail-Kontakt)
Letzte Änderung: 24. März 2017