Start Page > Ancient Greek and Latin on the Computer > Encodings of Greek
![]() Michael Neuhold Homepage
Michael Neuhold Homepage
Start Page >
Ancient Greek and Latin on the Computer >
Encodings of Greek
This English version of my German page is provided for convenience of those who do not speak German. I apologize for my poor English.
This document describes some of the most important possibilities of how accented Greek text can be digitally encoded on computers and to what extent they are supported by greekconverter.
Coding with 16-bit characters, on its way to a widely accepted standard. The canonical representation of letters with diacritics is a sequence of the letter followed by its diacritics. In many cases (as in Greek) a lot of possible combinations of characters and diacritics exist as precomposed characters, too (for compatibility with other systems and for convenience of font creation, I suppose). The stacking order for Greek diacritics is: breathing - accent - iota subscript resp. diaeresis - accent. Look, for example, at the dative singular of the feminine article:
| Canonical: 03C4 - 03B7 - 0342 - 0345 | |
| Partially precomposed: 03C4 - 1FC6 - 0345 | |
| Partially precomposed, another possibility: 03C4 - 1FC3 - 0342 | |
| Fully precomposed: 03C4 - 1FC7 |
Only the last one is fully supported by the conversion procedures of greekconverter because every combination is allowed in Unicode, even if it does not represent valid Greek (how should alpha + grave accent + acute accent + circumflex accent be handled on conversion?).
Unicode has a lot of advantages, no doubt, but also some drawbacks. It suffers from its attempts of being compatible to everything. So a lot of characters are defined several times with different codes, and who knows when to use which one, or to convert into what. Take, for example, the character that looks like a spacing (i.e. used as an character of its own rather than modifying the previous character) acute accent - ´ - :
00B4 ACUTE ACCENT: it's an acute accent (spacing), no
question here.0384 GREEK TONOS: the one and only accent used in modern
Greek (defined here because of compatibility with ISO-8859-7?).1FFD GREEK OXIA: one of the three ancient Greek accents,
according to Unicode code charts identical to 00B4 ACUTE ACCENT
(defined for another compatibility reason?).02CA MODIFIER LETTER ACUTE ACCENT: used for high tone,
primary stress, so what is the difference to 00B4 ACUTE ACCENT?2032 PRIME: used as abbreviation for minutes and feet.02B9 MODIFIER LETTER PRIME: used for primary stress /
emphasis - so this is sort of an accent, isn't it?0374 GREEK NUMERAL SIGN: indicates that Greek letters are
used as numbers; Unicode code chart says its identical to 02B9 MODIFIER
LETTER PRIME, but that is used for emphasis, which is something
completely different.Detailed code charts are available from the Unicode Consortium. The following charts are only to give you a first impression.
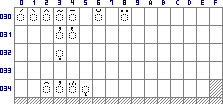 Combining Diacritical Marks (0300-036F). The grey positions have no characters assigned, the empty positions have characters that do usually not occur in Greek texts. Note that circumflex accent (0302), tilde (0303) and perispomeni (0342) are three distinct characters. |
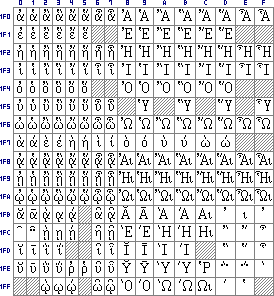 Greek Extended (1F00-1FFF). In earlier versions of the official Unicode charts the prosgegrammeni was subscripted below uppercase characters, in the current version it is adscripted (as usual in texts). This seems to be only a variation of font design. |
 Greek and Coptic (0370-03FF). The empty positions are the Coptic special characters which I was too lazy to draw. |
Unicode defines only the assignment between a character and a numeric value, but not how this numeric value is stored (number of bytes, byte order etc.). For this purpose exists UTF (Unicode Transformation Format). In UTF-8, e.g., characters from the area US-ASCII are stored using only one byte. This has the advantage that these characters can be interpreted correctly even by a text editor that is not Unicode-enabled.
7-bit safe coding using only US-ASCII characters, every diacritic is represented
by a character of its own (with only a few exceptions with spacing diacritics).
The example from above in Betacode: TH=|
(or th=|) - equal sign represents
circumflex accent, vertical bar represents iota subscript.
Greek Betacode is not case-sensitive, to denote a Greek capital letter it is
prefixed with *. Some projects use only uppercase letters (e.g.
TLG, for which Betacode was invented), others use only lowercase letters (e.g.
the Perseus project).
I could not find out if a certain stacking order for diacritics has to be
applied. But all examples I have seen so far use: breathing - accent - iota
subscript resp. accent - diaeresis (the latter being different from Unicode).
With Greek capital letters diacritics are placed between the *
and the letter itself (e.g. *)/ARHS), with lowercase letters
they are placed behind the letter (e.g. A)/RSHN).
Betacode, not unlike Unicode, encodes character functions, not character glyphs. Therefore a character glyph can have serveral encodings. The following three all look like the slash - / -:
%3: Slash, normal Roman typographic use#17: Lineola obliqua, ancient editorial sign#804: 1/12 obolBetacode has a lot of so-called escape sequences for editorial, papyrological, inscriptional, mathematical, musical, astronomical, metrical etc. signs and symbols. Most of them have no Unicode counterpart (at least none I know of) and greekconverter supports none of them.

Betacode key mapping in extracts
Transliteration with ASCII characters which skips the diacritics (except
rough breathing which is rendered as h) and renders some characters depending
on the preceding one (e.g. alpha-ypsilon is au
in most cases).
![]()
Replacement table for transliteration. Eta and omega are often simply rendered
as e and o (no difference to epsilon and omicron).
Since version 4.0 HTML uses the Universal Character Set (UCS) which is based
on the Unicode system. Since then any Unicode character can be noted as
numeric entity either decimal as ü or hexadecimal as
ü. For letters without accents there are named entities
like α. The example from above with HTML entities:
τῇ
(precomposed, named und hexadecimal numeric entities) or
τῇ
(canonical, only decimal numeric entities).
Alternatively you can create the HTML file in Unicode format and tell the
browser how to interpret the content of the file
by setting the charset-property in the meta-tag in the head-section:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
Proprietary 8-bit coding, optimized for displayal of Bible texts with
TrueType fonts, somewhat similar to Betacode. The example from above in
BibleWorks: th/|. If you use one
of the Greek True Type Fonts provided with BibleWorks (© Michael
Bushell), then the combining diacritics are placed above/below the previous
character by means of kerning.

The key mapping of BibleWorks, derived from the Greek TrueType font Bwgrkn,
compared to the Latin-1 key mapping.
The TrueType fonts SPIonic (© Scholars Press) and Sgreek (© Silver Mountain Software) mostly use the character mapping of Betacode. Like in BibleWorks the diacritics are placed by kerning. There exist the following differences from Betacode:
Sgreek has a whole lot more variants than SPIonic, and of course at different positions. Between Sgreek Medium and Sgreek Fixed there are some minor differences but one which is important: in Sgreek Medium, the pipe symbol | does not produce a iota subscript but a pipe symbol. You have to use #, $ and % in Sgreek Medium.

The key mapping of SPIonic. The characters with yellow background are
variants with slighter kerning. Note that SPIonic does not contain digits.
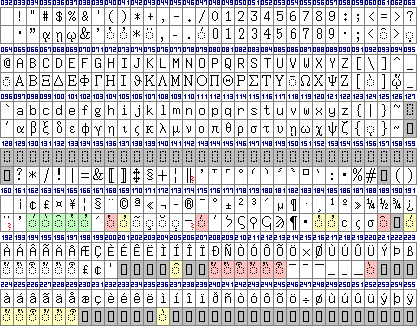
The key mapping of Sgreek Fixed. The characters with yellow background
have slighter kerning, the ones with red background have stronger kerning
than the standard characters. The ones with the green background have the
glyphs placed a bit more above the line. In some cases the Windows charmap
shows something different than WinWord. I do not know which one is
intended.
The conversion into SPIonic/Sgreek supports only characters that have the same key mapping in Betacode. In other words: kerning variants and combined diacritics are not supported.
8-bit coding, a quasi-standard on Apple computers up to OS 9 (since then MacOS supports Unicode). It avoids kerning and uses only precomposed characters instead. This has the drawback that constructs like MNE=MA IATRO= (tomb of a physician, used in accented renderings of inscriptions) cannot be displayed.

The key mapping of GreekKeys, derived from the True Type font Athenian (©
American Philological Association). Note that DisplayGreek has A(=| more
consequently at position 160, whereas in Athenian it is at 170.
The official character names of Unicode are not a coding by itself, but can be done by greekconverter for human readable output of erroneous Unicode text which cannot be converted otherwise.
Many other conversions may be achieved by multiple conversion. E.g. BibleWorks into GreekKeys: BibleWorks -> Unicode -> GreekKeys.
Currently not supported are codings which are invented for a single program, like Logos, WinGreek etc.
Author:
(contact by e-mail)
Last change: Mar 24th 2017