Startseite > DVD-Video > DVD-Grundlagenwissen > MPEG-Datenkompression
[ Vorige | Nächste ]
![]() Michael Neuhold
Michael Neuhold
Startseite >
DVD-Video >
DVD-Grundlagenwissen >
MPEG-Datenkompression
[ Vorige | Nächste ]
Die enorme Datenmenge, die bei der Digitalisierung von Film (d.h. der Verwandlung von Bild und Ton in Bits und Bytes) anfällt, paßt nur dann auf eine DVD, wenn man sie stark komprimiert. Die programmtechnische Realisierung eines Kompressionsverfahrens (in Windows z.B. in Form von DLLs) nennt man Codec (COder-DECoder).
Das bei der DVD üblicherweise verwendete Kompressionsverfahren ist MPEG-2. MPEG (sprich ['empeg]) ist Abkürzung für die Motion Picture Experts Group (Expertengruppe für bewegte Bilder), die Standards zur komprimierten Speicherung von Audio- und Videodaten ausarbeitet.
MPEG-1 und MPEG-2 basieren im wesentlichen auf folgenden Verfahren:
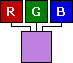 |
Graphikkarte und Monitor setzen jeden Bildpunkt (Pixel) aus Anteilen an rotem, grünem und blauem Licht (die drei additiven Grundfarben) zusammen. Das technisch einfachste Modell ist daher, für jeden Pixel je ein Byte für den roten, grünen und blauen Farbanteil zu speichern (RGB). |
Im TV- und Videobereich wird, auch aus historischen Gründen, ein anderer Farbraum verwendet: YUV. Hier besteht die Farbinformation aus einer Komponente für die Luminanz (Luma, d.h. Helligkeit) und zwei Farbdifferenzwerten für die Chrominanz (Chroma, d.h. Farbwert). Dieses Verfahren ist einerseits abwärtskompatibel zum Schwarzweißfernsehen (das eben nur die Y-Komponente anzeigt), und es entspricht andererseits auch besser der visuellen Wahrnehmung des Menschen, die Helligkeitswechsel genauer differenzieren kann als Farbveränderungen. (Bei der Helligkeitsinformation kommt es mehr auf die Menge der Informationen an als auf die Informationstiefe, bei der Farbinformation ist es genau umgekehrt.)
In MPEG werden die zu kodierenden Bilder in den YCbCr-Farbraum (einer Variante von YUV) übergeführt. Dabei werden meist für jeden 2x2-Pixel-Block vier Y-Werte (je einer pro Pixel), aber nur ein Cb- und ein Cr-Wert gespeichert (4:2:0 genannt). Das macht also 4+1+1 = 6 Byte für 4 Pixel statt 12 Byte im RGB-Format. (Neben 4:2:0 gibt es noch andere Möglichkeiten, z.B. 4:2:2, [für je zwei nebeneinanderliegende Pixel zwei Y-, aber nur je ein Cb- und Cr-Wert] oder 4:4:4 [für jeden Pixel ein Y-, ein Cb-, ein Cr-Wert].)
 |
 |
 |
 |
| Ausgangsbild | Y-Komponente | Cb-Komponente | Cr-Komponente |
Wie man sieht, ist die Helligkeitskomponente (Y) am aussagekräftigsten. Die beiden Farbkomponenten sind beim 4:2:0-Format nur ein Viertel so groß wie das Y-Bild, da immer für 2x2 Pixel ein Wert gemittelt wird.
Die drei Signalkomponenten werden jeweils in 8x8-Pixel-Blöcke zerlegt, und für jeden Block wird eine Diskrete Cosinustransformation (kurz DCT) durchgeführt. Dadurch wird das Bild in seine Frequenzanteile zerlegt, für jeden 8x8-Pixelblock wird eine 8x8-Koeffizientenmatrix berechnet. Da die hochfrequenten Bildanteile für die menschliche Wahrnehmung nur wenig zur Bildinformation beitragen, können sie vernachlässigt werden. Rechnerisch geschieht dies, indem die Koeffizienten so quantisiert (d.h. in ganzzahlige Werte übergeführt) werden, daß die Koeffizienten hochfrequenter Bildteile zu Null werden. Man durchläuft die Matrix dann so, daß eine Zahlenreihe mit vielen Nullen am Schluß entsteht. Diese Nullen lässt man einfach weg, indem man sie durch ein Blockendekennzeichen ersetzt. In weiterer Folge werden die so entstandenen Zahlenreihen verlustlos komprimiert, zuerst durch Lauflängenkodierung, anschließend durch Huffmankodierung.
Durch die Quantisierung können Pixelmuster entstehen, die im Ausgangsbild nicht vorhanden waren. Bei hoher Komprimierung bleibt im Extremfall für einen 8x8-Pixelblock nur ein Koeffizient übrig. Je stärker die Komprimierung, umso deutlicher werden die Blöcke sichtbar, es entsteht ein Klötzchenmuster. Diese Bildfehler bezeichnet man als Kompressionsartefakte.

 |
 |
| JPEG-Bild mit mäßiger Komprimierung. Der Hintergrund war im unkomprimierten Bild einfarbig grau. Die Ausschnittvergrößerung zeigt ein durch die Kompression entstandenes "Pixelgrießeln". | JPEG-Bild (die Affenfamilie aus "Schweinchen Babe in der großen Stadt") mit hohem Kompressionsgrad (1.488 Bytes), deutlich sind hier die 8x8-Pixel-Blöcke der DCT zu sehen. (Das Ausgangsbild braucht als RGB-Bitmap 53.654 Byte.) |
Der umgekehrte Vorgang, das Berechnen von Pixel aus den DCT-Koeffizienten, heißt Inverse Diskrete Cosinustransformation (kurz iDCT).
Wenn man aufeinanderfolgende Bilder eines Filmes betrachtet, sieht man, daß von Bild zu Bild nur geringfügige Veränderungen eintreten. Das nutzt man bei MPEG zur Reduktion der Datenmenge. Ein zur Gänze (d.h. ohne Bezugnahme auf vorangegangene oder nachfolgende Bilder) gespeichertes Bild heißt I-Frame (intraframe).
Bei der sog. motion estimation oder motion prediction wird das vorangegangene Bild in Makroblöcke von 16x16 Pixel zerlegt und dann das aktuelle Bild nach diesen Blöcken durchsucht (der Einfachheit halber wird das nur mit der Y-Komponente gemacht). Für hunderprozentig passende Blöcke braucht man gar nichts zu speichern. Für halbwegs passende Blöcke wird ein Verschiebungsvektor gespeichert, zwei Zahlen, die angeben, um wieviel der Block sich verschoben hat. Zusätzlich wird ein Bild mit Differenzinformation erstellt. Blöcke, für die gar keine Entsprechung aus dem vorangegangenen Bild gefunden werden kann, werden wie I-Frame-Blöcke kodiert.
Ein solches Bild, das über Verschiebungsvektoren auf das vorangegangene Bild Bezug nimmt, heißt P-Frame (predicted frame). Ausgangsbild für ein P-Frame kann ein I-Frame oder ein P-Frame sein.
 |
1. Bild n-1 in Makroblöcke zerlegt |
 |
2. zu kodierendes Folgebild n |
| 3. Sechs Blöcke, die sich zwischen n-1 und n verschoben haben | |
 |
4. das Bild n durch bloßes Anwenden der Verschiebungsvektoren |
| 5. Differenz zwischen 2. und 4. | |
| 6. neu hinzugekommene Blöcke |
Der Decoder generiert das Bild aus einem P-Frame grob gesagt folgendermaßen: er nimmt das vorhergehende Bild n (1.) und wendet darauf die im P-Frame gespeicherten Verschiebungsvektoren an. Das so entstandene Bild (4.) wird mit dem Differenzbild (5.) verknüpft. Dann werden die neuen Blöcke (6.) hineinkopiert. Das Ergebnis (2.) kann als Ausgangspunkt für das nächste P-Frame dienen. Da die Differenzblöcke mit DCT komprimiert werden, entstehen geringfügige Bildfehler, die sich nach einigen tausend P-Frames soweit aufkumuliert hätten, daß das Bild bis zur Unkenntlichkeit entstellt wäre. Darum muß man von Zeit zu Zeit wieder ein I-Frame einfügen.
Auch damit man an eine beliebige Stelle im Film springen oder ihn rasch zurücklaufen lassen kann, muß ein Film von Zeit zu Zeit I-Frames enthalten. Zusätzlich sieht MPEG auch sog. B-Frames (bidirectional predicted frame) vor. Sie beziehen sich sowohl auf ein vorangegangenes als auch auf ein nachfolgendes Bild (I- oder P-Frame). B-Frames werden selber nie als Referenz verwendet. Da zur Darstellung eines Bildes aus einem B-Frame der Decoder beide Referenzbilder kennen muß, müssen die Frames in anderer Reihenfolge gespeichert als wiedergegeben werden. Es gibt keine Vorschriften, ob und wieviele P- oder B-Frames zu verwenden sind, aber meist läßt man zwei B-Frames aufeinander folgen. Eine typische Framesequenz sieht so aus:
| Wiedergabereihenfolge | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| Frametyp | I | B | B | P | B | B | P | B | B | P | B | B | I |
| Speicherreihenfolge | 1 | 4 | 2 | 3 | 7 | 5 | 6 | 10 | 8 | 9 | 13 | 11 | 12 | Frametyp | I | P | B | B | P | B | B | P | B | B | I | B | B |
Diese zwölf Frames bilden genau ein GOP (s. dazu den Abschnitt über die Dateistruktur). Man kann diese GOP-Struktur bei manchen Video-CDs als Pulsieren des Bildes (ungefähr im Sekundenrhythmus) wahrnehmen: zwischen den I-Frames verschlechtert sich die Bildqualität merklich; es entstehen Artefakte (insbes. in dunklen Flächen als deutliche Klötzchen), die mit dem nächsten I-Frame wieder verschwunden sind.
Wenn ein Graphikchip iDCT oder motion compensation in Hardware unterstützt, beschleunigt das im Allgemeinen den Dekodiervorgang und entlastet den Hauptprozessor.
Autor:
(E-Mail-Kontakt)
Letzte Aktualisierung: 27. April 2004